
Progress, plans, and premises in AI safety – slides and talk transcript

On November 8th, I gave a 30-minute talk to OAISI. These are the slides and a (lightly edited) transcript of my talk.
I think this talk tried to do too much and too quickly: nonetheless, I thought it might be interesting to some people. There’s much more that could be said or disagreed with, feel free to ask questions or argue with me in the comments.
As usual, these views are my views, not my employer’s – and in this particular case, I was giving this talk in my personal capacity. You shouldn’t take anything I say here to be “Coefficient Giving’s views on X”.

All right, thanks for having me. I was gonna start by introducing myself, but it’s been capably done, so I can skip most of that. I’m a grantmaker, I work at Open Philanthropy [AN: this talk was given pre-rebrand — I work at Coefficient Giving now!], and we’re hiring—that’s the one thing that wasn’t mentioned—so if you’re into AI safety and governance and want to work in this space, consider applying.

Okay, what am I doing with this talk? Hopefully four things.
First, some of my quick takes on what’s going on in AI.
Secondly, some takes on work in, and plans for, AI safety.
Third, some working views or assumptions people often have in AI safety and governance work, and the strategic implications if they’re false.
And fourth, I’ll say a bit more about what you could do if you’re interested in AI safety and governance.
Before I start, can I get a hand poll for familiarity with AI and AI safety stuff? Up here [gestures] is “I’m really in the weeds, I read the Alignment Forum every day,” and then [gestures] down here is “I don’t know very much about it, I’m just curious.” [checks audience] Okay, great. I’m afraid some of you might get bored and some of you might get confused—feel free to ask questions as we go, or zone out until I get to more interesting material.
What’s going on with AI?
This is my speedrun of things that happened in the last year that I think are important.

First up: reinforcement learning finally works! I think this year was the year of RL actually working. For a long time we’ve had LLMs, they do stuff, they’re kind of good at some of that stuff, but I think recently the frontier AI developers finally cracked using reinforcement learning to make them very good on at least verifiable tasks, mostly math and coding.
I put a graph on there—because everyone loves a graph—showing model performance on math evaluations over time. Other news: this year Gemini got a gold medal at the IMO. So at least in some narrow sense, LLMs do seem a lot better than most humans at some tasks. I mean, I was writing this slide and I was like, oh man, maybe some people in the audience will actually have gold medals at the IMO – but I do not have a gold medal at the IMO, so it’s at least better than me in some domains.
Also this year, I claim agents are finally somewhat and sometimes useful, at least for coding. This was the year of vibe coding: this is a photo of Rick Rubin, who’s a music producer, but he also wrote an essay on vibe coding with Anthropic.
Yeah, so agents—that is, AI systems running somewhat autonomously, given very high-level descriptions of what they should do—are sort of useful sometimes for coding. They’re also kind of unhelpful in some ways: lots of people talk about Claude Code accidentally deleting their entire home directory if they let it run for too long, and also coming up with other ways to make sure it can delete it even if you explicitly say you can’t use remove commands.
People have been saying that it’s the “year of AI agents” for a while, but maybe it’s finally starting to become kind of true. And in the future, I expect agents to get more reliable and better at doing long-horizon tasks, which I think is a big deal—maybe I’ll talk a bit about that later.
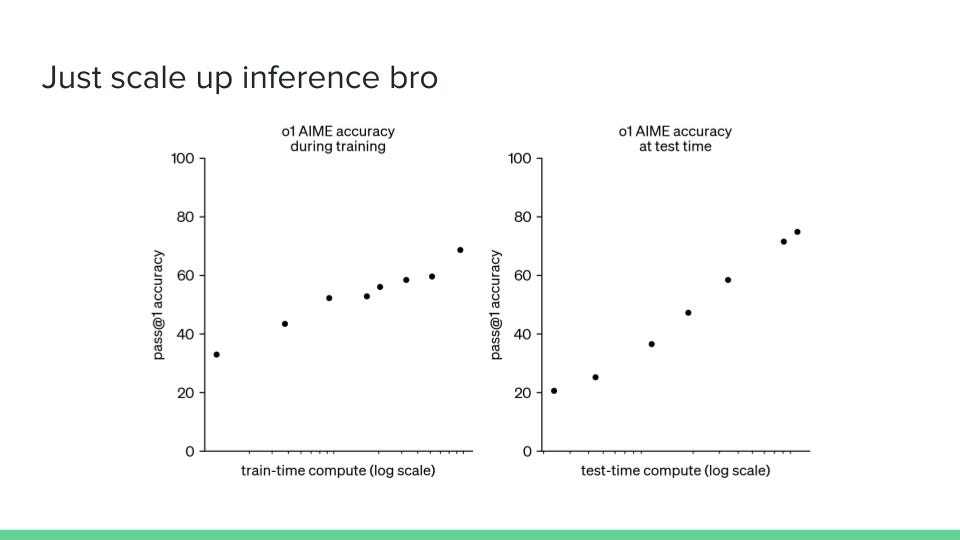
Also this year: scaling up inference compute now works. Turns out if you just let the models generate more tokens when they’re answering, they do better at stuff. This is a nice graph from Toby Ord: The X-axis is log scale here, so the curve depicted, if it were a linear scale, would be steeper. This is showing: if you ask o1 to answer questions on AIME, given one attempt, how accurate is it, and how does that vary with the amount of compute? In particular, the second graph shows that as test-time compute—that is, inference compute—increases, models perform more accurately.
You might be like, why does this matter? I think for a long time the way we were getting better performance out of LLMs was mostly by training bigger and bigger models—so spending more compute at train time (that’s the left-hand graph). At least this year, it seems like we’ve come up with somewhat better ways to spend compute at test time and improve performance.
In general, this means you might not have to train as large models to achieve similar performance; it also means that different actors may increasingly have access to different levels of capabilities, depending on how much they can afford to spend on inference.

So what are some interesting implications from this?
First, AI capabilities are really lumpy. They’re a lot better than humans on many hard tasks and a lot worse on many easy ones. This is a screenshot of, I think, poor GPT-4 trying to look at a Minesweeper board, and really quite confidently failing to see it correctly and notice where the zeros and ones are.

Second, models are now sometimes aware when we’re testing them, and will tell you about this if you ask them or monitor their chain of thought. These are some figures from papers that Apollo did with OpenAI: I think the transcripts of the model’s reasoning are very interesting, I recommend taking a look.
The TL;DR here is that for a long time, the best way to figure out how good models are at stuff has been to either use them yourself, or get someone to run an evaluation on them. We do this for dangerous capabilities as well as interesting and economically valuable capabilities, because if models have scary capabilities, it’d be good to know that Now, models seem to notice that they’re in an evaluation. This obviously could be bad, if models do in fact have dangerous capabilities and want to hide them so they can get released.

Models are also now scheming, in at least somewhat contrived situations. By scheming, I mean: doing stuff that the user explicitly wouldn’t want and then hiding this from the user. On the left-hand side we have a model trying to preserve itself and avoid being shut down, and on the right-hand side we have a transcript where models sabotage some answers, i.e. they deliberately underperform on some tests, to make sure they still get deployed.
These situations are kind of contrived, and maybe I can talk about this if there’s time for questions afterwards, but this is interesting empirical evidence of some relevant AI risks.
What next?

Okay, that was the whistlestop tour. What’s coming next? These are very hot takes—you should probably argue with me about them.
It seems like models are getting very good at easy-to-verify tasks like math and coding, but hard-to-verify tasks—I put “creativity” in scare quotes here—are not improving at a similar speed. My best guess is that this will continue. If that’s right, then you should expect the AI capabilities landscape to continue to look very lumpy, or even lumpier, when you get models which are world-class at some narrow sets of tasks, and then just not very good at other sets of tasks. In particular, I think we might be in a world where models are world-class at engineering and writing code to solve well-scoped problems, and then quite bad at things like research taste or conceptual reasoning.
Some other rampant speculation here: I think it’ll be interesting to see how fast models improve at long-horizon tasks. Right now I think a key consideration for AI safety folks is something like: should we expect models to continue improving at long-horizon tasks at roughly the same rate as they’ve been improving the last two years (which, spoiler, is very fast)? Or should we think that’s going to slow down somewhat?
Other thoughts: returns from pre-training are maybe diminishing? Seems like most recent good models have not had as big jumps in pre-training as previous good models did (when compared to their corresponding previous generations). For example, Grok 4 didn’t have that much pre-training, mostly xAI just did tons of RL.
There is other, more half-baked speculation on that slide, we can talk about it in the Q&A.
So that was my tour: inference scaling, agents and vibe coding, evals awareness and scheming, models finally getting very good at verifiable tasks. That’s what I claim is going on in the landscape of AI.
What’s the plan for AI safety?

I want to talk a bit now about what I think is going on with AI safety specifically.

First, at a high level, I think it’s helpful to have some taxonomy in your head when you think about what kind of research is going on in AI safety. Here I’m mostly talking about technical AI safety—I can talk about AI governance at some other point.
Here are the rough clusters I use:
Empirical research on understanding existing models. Things like: evaluations, interpretability, safety cases where you look at some model and say “how dangerous does it seem in this domain?” and then weigh up the evidence and write some arguments for and against.
Theory — understanding future models too. Again, there’s some interpretability stuff going on here. This bucket includes things like debate, scalable oversight, blue-sky alignment research, and agent foundations.
AI control — roughly speaking, how do you get useful work out of AI models that you don’t trust fully?
Safe by design. Roughly, the thought here is: you might think that training current LLMs to be general agents is kind of dangerous. And if that’s the case, rather than trying to tack on stuff to them to make them safer, maybe we should just have totally different and safer architectures or ways of designing AI systems. Think e.g. Yoshua Bengio on scientist AI, also “tool AI”.
And finally, a cluster I’ve called “Sociotechnical?”. This is a very vibes-y bucket: in my head this is multi-agent research, cooperative AI, something something gradual disempowerment research, something something interfacing with the rest of the world.
I have a QR code with some links at the end of this talk, but if you want other divisions or better overviews of AI safety, the two things I recommend right now are:
My colleagues in the technical AI safety team at Open Phil have a list of research areas they’re into.
It’s obviously not a complete set of all possible research areas, but it’s fairly broad and I think fairly well explained.
Okay, that’s the research landscape. What’s the overall strategy? I think there are two broad camps.

Camp one is muddling through. I think you are in this camp if you’re either quite optimistic about safety or quite pessimistic about any substantive change on AI progress/safety awareness. The muddling-through camp is roughly like: well, things will probably continue as they have always continued: models will get better at a pretty fast rate, we’ll remain pretty confused about what they’re actually doing, but probably with some kind of hodgepodge of filters and safeguards and oversight and evaluations and societal resilience, things will mostly be fine, we will roughly understand what kinds of benefits and risks we get from AI models, and we’ll be able to mitigate the worst-scale risks to an appropriate level.
Then there’s the other camp, which I think people are usually in if they’re much more worried about AI safety or more optimistic about getting agreement on risks from AI, or some combination of the two. They’re like: “This is crazy, we’ve got no idea what’s going on, we should slow it down, or we should shut it all down.”
In the sub-bullets, I’ve tried to gesture at some of the work I think people like if they’re in each of these camps. And happily, as you might notice, I think there’s a lot of overlap between these two camps. In particular, I think both camps are quite interested in increasing evidence and buy-in and interest in AI safety from key decision-makers, so they’re interested in evals and demos and tracking real-world incidents I think the main way in which they differ is something like: whether they want to spend political capital now, to slow down or stop AI progress, or whether they want to bank it for the future, or make what they consider more targeted, lower-cost asks.

So these are some orientations to AI safety you can have. But what is the plan, actually? I think the main plan that people talk about with AI safety—although there are lots of different views on this—is roughly: we’ll either get the AI to do our homework (the alignment problem) for us, or we’re going to buy enough time that humans are going to figure it out for us.
My former colleague Joe Carlsmith has a nice series of essays on this, which I recommend reading if you’re interested in learning more about this high-level plan. But I think the fundamental story here is something like: we’re just gonna need lots of labor from very smart beings thinking really hard about AI safety in order to get the risk down to an appropriate level. And either this will come from using AI to do that work for us, or it’ll come from humans, given more time, with some slowdown of AI progress. And the end goal is the same for both of these stories—that we can make true and rigorous claims about the safety of AI systems, and then we can widely deploy them and great stuff will happen.
I have some slides on the “getting AIs to do our homework for us” story, but I think this is fairly in the weeds, so I’ll skip it for now and maybe come back to it at the end if we have time. [AN: we did not have time.]
So again, this was quickly discussed, but: this is what I think of as the kinds of work happening in AI safety, and the general plans that people have.
Action-guiding assumptions

Next I want to talk a bit about what I see as some action-guiding assumptions in AI safety and governance that people often hold. I think one useful exercise you can do is, one, think about whether you agree or disagree with the assumptions, but also: what are the implications if they’re false? Or, to the degree that you’re less confident in them, how should things be different?
I’ve found thinking about these assumptions kind of helpful for figuring out: what do people take to be common knowledge, or what’s the jumping-off point for thinking about AI safety and AI policy? And these are all just my sense of some of the assumptions, and quickly generated, so I’m not claiming that everyone would agree with me.
But yeah, let’s talk about them. I’ve now caveated a bunch. Here are some reasonably common assumptions, according to me. I’m gonna go through them and then I’ll talk a little bit about my best guesses about how things might be different if these assumptions are false. But I would encourage you to also try and form your own thoughts and notice where you disagree with me.

Okay, some common assumptions:
Closed-weight models are just gonna be more capable forever when compared to open-weight models. So the leading closed weight AGI companies – OpenAI, Google DeepMind, Anthropic, maybe SSI, Thinking Machines, etc.—their models are just gonna be better than whatever the open-source equivalent is.
It’s probably good to slow down the AI progress of authoritarian regimes.
Probably we’ll get some kind of warning shots before we get to catastrophes or AGI. By “warning shots” I mean some big scary public event, like a bad actor uses AI to help them with a large-scale cyber attack or something similarly scary, which causes many people around the world to sort of sit up and take notice.
Probably we’ll get agents rather than tools, i.e. we’ll get AI systems with world models, which have plans and intentions and can reason about other beings pretty well.
Probably LLMs are the way we’ll get to AGI.
Probably intent alignment—the narrow problem of getting the AI system to do roughly what some user or the model developer intends—is neither extremely easy nor extremely hard: It’s probably either pretty hard or pretty easy or somewhere in the middle.
I’m seeing some frowns, and you can argue with me afterwards if you think these are not assumptions people hold.

Two days ago, Kimi K2 Thinking came out. I haven’t looked at it very much, but I thought it was kind of interesting, because it does seem to be doing a lot better than many closed-weight models on many benchmarks. Benchmarks are flawed in a bunch of ways, and we can talk about that later, but I wanted to give you some suggestive reason to think that perhaps the “closed-weight is better than open-weight” assumption might not hold forever. [AN: since my talk, it seems that Kimi is cooked.]
How would the picture be different if that was false? I think in a couple ways.

First, the “safety tax”, i.e. the cost of implementing safety measures, becomes much more important. I think some people in AI safety right now have this model where if we could figure out something to do that would meaningfully increase the safety of AI systems, then if we can also convince two or three major AI companies to adopt this measure, then we’re probably fine—we’ve reduced a large amount of the risk. And also many (although not all) of the major AI companies are somewhat sympathetic to AI safety, so it might be okay if that safety measure is kind of costly for them.
For example, I think their model is that if you went to Anthropic tomorrow and said “Oh I have this great new thing and it’s going to really accurately prevent all cyber misuse, but it’s gonna increase inference latency by 5%,” I think their model is that Anthropic will be like “Okay yeah, that’s a good trade, it doesn’t matter if it’s kind of costly.”
Obviously, if open-weight models are better than closed-source models, then you’re not in the world where you’re convincing two or three developers: you’re in the world where you’ve got to get all these open-weight model developers to do the safety stuff you want them to do. So the safety tax becomes much more important. Similarly, coordinated pausing of AI progress looks much harder.
There are some upsides too though. Doing AI safety research outside of AGI companies looks much better in this world: currently, I think there are some situations where you need to be working on the most capable models, and so it’s pretty helpful to be at an AGI company doing that, and also, the safety of those models matters the most because they’re the most capable. But obviously, if open-weight models are better, neither of these things is true anymore.
More speculatively, maybe you should be less worried about concentration of power if open-weight models are pretty good. I haven’t thought this through very much. Also, maybe you should think more about things like data filtering in pre-training to stop models having these dangerous capabilities in the first place.
Maybe you should do more work on societal resilience: you should assume that the ability to cause harm will be more widely distributed, and so it’s more important that we can respond to it well and it doesn’t affect us overall very much.
Okay, here’s one final assumption I’ll talk about, and then I’ll get onto the “what can you do?”.
Lastly, one model I think people have of how AI safety and governance goes well is something like this: there’s the AI safety crowd who are very worried about the risk from AI. And then there is the rest of the world, who are mostly not worried and think the AI safety crowd might be overhyping it, or are somewhat skeptical, or are excited about the economic benefits.
And the AI safety crowd have this story of: “Well, we will first generate a bunch of evidence of AI capabilities, via doing things like evals and demos and noticing how helpful AI is in everyday life. And then the rest of the world will take AI in general more seriously. Then, second, we’ll try and convince them of the risks from AI, and we’ll do so by having these evaluations for dangerous capabilities. But also, worst-case scenario, and this would be really bad, but: if we really can’t get our act together, one thing that will probably happen is that some bad actor—some cyber-attacker, say, or someone motivated to do bioterrorism—will try and do something bad using an AI, and the AI will substantially help them. And then the rest of the world will see this and go ‘Whoa, this AI stuff is a big deal,’ and will sit up and take notice, and then we’ll have broad consensus on the risks as well as the benefits of AI.”
I think this story, of warning shots before catastrophe, is a story many people are relying on.
There are many different people trying to track AI incidents in the wild: I’ve linked the AI Incident Tracker and the AI Risk Explorer. Google has a blog about cyber threats where they publish updates about AI uplift for cyber attacks. And Holly Elmore has a blog post on the myth of AI warning shots, which I think is pretty good.

So, I think “we’ll get warning shots” is a working assumption many people hold. And I think if it’s false, we’re in kind of a bad spot. Some things that might be different:
First, we’d need our evaluations to be much more rigorous so people actually take them seriously, and much more relevant. We’d also need to be running them more often, I think, especially when models are only released internally at AI companies.
We’d probably also need to do things like improve the quality of AI demos to convince people of risks, without having major real-world incidents. Maybe we’ve also got to empower whistleblowers at top AGI companies, so that if they see concerning stuff internally, they can report this.
An exercise for the reader

As an exercise for the viewer, I’ve listed some other assumptions I think people hold. Maybe through this course, or right now, it could be interesting either to think about these assumptions, or to generate some other assumptions that you notice many people seem to share. Then, you could first think about what that implies for AI strategy, and secondly, how AI strategy would change if they were false.
I think one productive frame for orienting to your reading is something like: is there some set of views these people mostly share, or at least, mostly take to be the dominant view? What do they imply, and what would happen if they were false? And then also: what would change my mind about these views? What would I need to see to be convinced of the opposite?
What can you do?

Lastly—okay, I’ve talked quite a lot and at quite a rapid pace—but I want to quickly talk about what you could do if you’re interested in AI safety and AI governance work.
So here’s the advice I’ve gotten, distilled:

First, there’s still tons of alpha left in having good takes. You might be surprised, because there’s many people doing AI safety and governance work—but I think there’s still plenty of demand for good takes, and you can distinguish yourself professionally by being a reliable source of them.
How do you have good takes? Holden Karnofsky has a great blog post called “Learning by Writing,” which I strongly recommend. I think the thing you do to form good takes, oversimplifying only slightly, is you read that blog post and you go “yes, that’s how I should orient to the reading and writing that I do,” and then you do that a bunch of times with your reading and writing on AI safety and governance work, and that’s how you have good takes.
There’s more obvious foundational stuff, like you should probably know roughly what you’re talking about. I listed a bunch of resources. I expect you’re familiar with many of them, and if not, they’re gonna be in the QR code at the end.

I also keep telling people to do writing: here’s some especially useful kinds of writing you could do.
What is less useful usually, if you haven’t got evidence of your takes being excellent, is just generally voicing your takes. I think having takes and backing them up with some evidence, or saying things like “I read this thing, here’s my summary, here’s what I think” is useful. But it’s kind of hard to get readers to care if you’re just like “I’m some guy, here are my takes.”
In order to get people to care about your takes, you could do useful kinds of writing first, like:
Explaining important concepts, I’ve listed some
Collecting evidence on particular topics
Summarizing and giving reactions to important resources that many people won’t have time to read
For example, if someone from this group wrote a blog post on “I read Anthropic’s sabotage report, and here’s what I think about it,” I would read that blog post, and likely find it useful.
Other good stuff you can do includes writing vignettes, like AI 2027, about your mainline predictions for how AI development goes.
Okay, and now, some especially useful kinds of empirical projects.

This is a classic list, I’m not gonna spend very long on it, but broadly:
Reproduce papers
Port evals to Inspect
Do the same kinds of quick and shallow exploration you’re probably already doing, but write about it—put your code on the internet and write a couple paragraphs about your takeaways, and then someone might actually read it!
I put some ideas for interesting topics that you could think about here, but you can just generate them yourself by going, “What am I interested in?”

I think some kinds of work are especially neglected. And if you read these and think about them and think they sound interesting, you should especially consider working on them.
And lastly, I have a great meme.

I think there are many topics in AI safety and governance where nobody’s on the ball at all.
And on the one hand, this kind of sucks: nobody’s on the ball, and it’s maybe a really big deal, and no one is handling it, and we’re not on track to make it go well.
But on the other hand, at least selfishly, for your personal career—yay, nobody’s on the ball! You could just be on the ball—there’s not that much competition.
So if you end up doing this course and thinking more about AI safety and governance, you could probably pretty easily become the expert in something pretty fast, and end up having pretty good takes, and therefore just help a bunch. Consider doing that!
Okay, that was my talk. Thanks! Any questions?
Appendix: List of (some of the) resources referenced in my talk
From my talk
https://coefficientgiving.org/funds/navigating-transformative-ai/, https://coefficientgiving.org/funds/navigating-transformative-ai/request-for-proposals-ai-governance/
https://www.tobyord.com/writing/inference-scaling-reshapes-ai-governance
https://theaidigest.org/village, https://theaidigest.org/village/blog
https://www.antischeming.ai/
https://www.apolloresearch.ai/blog/more-capable-models-are-better-at-in-context-scheming/
https://www.lesswrong.com/posts/fAW6RXLKTLHC3WXkS/shallow-review-of-technical-ai-safety-2024

https://joecarlsmith.com/2025/02/13/what-is-it-to-solve-the-alignment-problem and follow-ups
https://epoch.ai/gradient-updates/why-china-isnt-about-to-leap-ahead-of-the-west-on-compute
https://airisk.mit.edu/ai-incident-tracker, https://cloud.google.com/blog/topics/threat-intelligence/threat-actor-usage-of-ai-tools, https://www.airiskexplorer.com/, and

https://www.aisafety.com/self-study, https://airtable.com/app53PsYpHxJW61l3/shrQSYXSW9z96y5WE, https://airtable.com/app53PsYpHxJW61l3/shrQSYXSW9z96y5WE
https://ai-2027.com/, and https://www.lesswrong.com/posts/yHvzscCiS7KbPkSzf/a-2032-takeoff-story (for the reflections/encouragement)
https://nostalgebraist.tumblr.com/post/787119374288011264/welcome-to-summitbridge
https://alignment.anthropic.com/2025/unsupervised-elicitation/, https://arxiv.org/abs/2405.19550, https://www.alignmentforum.org/posts/jsmNCj9QKcfdg8fJk/an-introduction-to-ai-sandbagging
Other resources
https://80000hours.org/
Sudhanshu Kawesa’s public doc of AI safety cheap tests and resources: [Shared externally] AI Safety cheap tests and resource lists
Hi Catherine,
Thanks for posting the slides and the transcript from your talk, I found it very interesting and will be keeping an eye on future developments.
I have an article coming out today which is a personal experience piece and I would very interested to get your comments on it. The article outlines the need to be “nice” when communicating with AI.
https://open.substack.com/pub/andybeattie/p/when-we-stop-saying-please-to-machines?r=6yzydt&utm_campaign=post&utm_medium=web&showWelcomeOnShare=true